智能手机感知理解驾驶行为:目前的实践和挑战
摘要
理解驾驶行为——即使是在自动驾驶技术迅速出现的情况下——仍然是人们关注的焦点,这有助于分解复杂的驾驶动力学,开发用户友好且可接受的自动驾驶汽车,并确保自动驾驶汽车和传统汽车在道路上安全共存。移动众感技术已经成为理解和模拟驾驶行为的一种手段。虽然通过智能手机收集数据的优势有很多(速度、准确性、成本低等),但挑战包括但不限于准备速度、处理需求,以及方法、立法和安全问题,都是巨大的。本文旨在回顾基于智能手机传感器数据流分析驾驶行为的研究。我们首先建立一个包容性的逐步框架来描述从数据收集到知情决策的路径。接下来,对现有的文献进行了深入分析,并对数据收集和数据挖掘实践方面的挑战进行了批判性的讨论,特别强调了使用手机收集驾驶数据以及使用人群感知数据进行特征提取的局限性和关注点。随后,建模驾驶行为实践和端到端解决方案的司机协助和推荐系统也进行了回顾。本文最后讨论了文献中出现的最关键的挑战和未来的研究步骤。
介绍
驾驶行为对于维护安全(Sagberg et al., 2015)和可持续交通(Huang et al., 2015)起着决定性的作用。2018)。除此之外,它还会影响交通流量、燃油消耗、空气污染、公众健康以及个人心理健康。
对于“驾驶行为”或“驾驶风格”这一概念已经给出了许多定义(Sagberg et al., 2015)。这里我们接受了Lajunen和ozkan(2011)给出的定义:“驾驶风格涉及个人驾驶习惯——即驾驶员选择驾驶的方式”。大量的文献强调了在交通条件、排放、压力缓解等方面采用安全和环保驾驶行为的好处。
从宏观的角度,特别是在交通管理和控制领域,驾驶行为是非常重要的,因为特定驾驶行为与交通拥堵水平显著相关;
从微观的角度,推荐和驾驶辅助系统对于改善个人驾驶行为和提高驾驶员对其驾驶方式影响的认识至关重要。
驾驶员在选择加速和减速的方式、与前车的距离以及是否超过限速(超速)方面存在差异(Miyajima et al., 2007;Mantouka等人,2019年)。
因此,在有关交通和道路安全的文献中已经确定了几种驾驶概况。激进驾驶已经得到了广泛的研究,
- 大部分研究集中在识别严重的加速和制动事件(Kalra和Bansal, 2014;Eboli 2016)
- 大量的研究对危险驾驶进行了调查,这些研究大多是指超速驾驶,甚至无视交通标志和规则(Harbeck and Glendon, 2018)。
- 在过去的几十年里,在温室效应的影响下,许多研究都侧重于通过识别所谓的生态驾驶来分析能有效消耗燃料,从而减少空气污染物的驾驶习惯。此外,还会对驾驶员的驾驶行为进行调查,如超速、酒后驾驶和驾驶时使用手机(Ma et al., 2017)。
最普遍的驾驶概况包括:
- Aggressive driving:激进驾驶,如紧跟在后tailgating,剧烈加速harsh acclerating,刹车braking和转弯cornering,不正确的换道improper lane changing等等(史密斯等,2016)
- Distracted driving:分心驾驶,如分心驾驶,如发短信、吃东西、喝饮料或打电话,也就是驾驶员在驾驶时注意力不集中(chen et al. 2015)
- Risk taking:风险承担/勇于冒险,例如超速驾驶,违反交通规则或与前车距离过近
- Eco-driving:环保驾驶,即节能驾驶,从而最大限度地减少污染
- Safe driving: 安全驾驶,正常低风险驾驶行为
在自动驾驶汽车时代,除了确保交通安全和可持续发展,了解驾驶行为对于开发用户友好且容易接受的机器仍然至关重要。对于用户的接受度来说,自动驾驶汽车不仅要安全可靠,更要提供舒适的用户体验。类人自动驾驶的风格是这项新技术被大众接受的关键。为了训练机器像人一样驾驶,更好地理解驾驶员的驾驶方式非常有用(库德勒等人,2015:Dong等人,2016)。开发能够模拟实际驾驶员行为并以类似方式做出决策的适当软件,是将自动驾驶完全融入日常生活中最具挑战性的任务之一。
综上所述,很容易理解理解和彻底调查驾驶行为是非常重要的。智能手机的高渗透率极大地推动了数据收集的速度、频率和准确性。这样就可以收集到大量的自然驾驶数据,这些数据通常用于调查驾驶行为,检测不安全驾驶习惯,预测路网状况。
为了从多个传感器和设备的数据中提取有意义的信息,以及是否有可能依靠智能手机数据中的驾驶信息来决定政策和决策,这些任务的实施产生了许多问题。
尽管最近的一些研究试图回答这些问题(Ferreira Júnior et al., 2017; Chan et al. 2019),研究人员大多只关注这一现象的一个方面,而没有解决从数据收集到结果利用的所有必要阶段出现的问题。
- Chan et al.(2019)对驾驶行为检测算法进行了全面综述,特别强调了它们的性能和精度度量。
- 在同样的背景下,其他研究人员FerreiraJúnior et al.(2017)列出了当前的机器学习(ML)并进行了一个真实世界的实验,以评估比较结果在驾驶事件分类全文笔记
在这项工作中,我们扩展了对驾驶行为的分析,将重点放在从数据收集到建模和决策的海量智能手机传感中揭示行为洞察力的具有挑战性的方面。
最后,本文的目的是提出一个包容性的方法框架,以理解驾驶行为通过智能手机传感和协助研究人员选择最合适的工具和方法时,处理驾驶分析。
- 首先,概述了所提议的框架。
- 随后,最近的文献分析和批判性评估一个显式的关注的主要挑战出现在数据收集和存储、数据准备、数据挖掘、建模的驾驶行为和司机作出最终决策和推荐系统,我们将讨论未来的研究方向和总体的结论。
从智能手机数据到知情决策:一个分析框架
将智能手机传感器转换成有意义的驾驶行为信息,不是一个简单的过程。
数据方面,理解数据
- 首先,从智能手机收集的数据通常存在质量问题,并且含有大量的噪音,因为它们受到道路状况和智能手机在车中的位置的显著影响。
- 此外,在监测阶段使用的传感器种类繁多,如加速度计、陀螺仪、GPS等,导致在内容和质量方面具有大量不确定度的多源数据集。
- 利用这些数据集进行驾驶行为调查的首要步骤包括对数据的理解。这一步包括所有程序的数据清洗,数据噪声排除和几个其他预处理技术。
提取特征
- 随后,可以从与行程和驾驶相关的数据中提取有趣的特征。
- 在驾驶分析中,与行程相关的特征是指模式检测和驾驶员-乘客的区别。
- 在一些研究中,模式检测系统已经被开发出来。以聚合的水平(机动化和非机动化) 或分解的水平(公交、地铁、汽车、步行等) 进行预测(Nour等,2015:Shin等,2015)。
- 其他研究集中在通过使用ML技术利用智能手机数据来识别用户是司机还是乘客(Ahmad等,2019)
建模
一旦研究人员完全了解他们掌握的数据类型,驾驶行为的建模就会随之展开。
现代计算机巨大的计算和存储能力允许处理大量数据和开发能够确定最复杂行为和模式的复合模型。
到目前为止,研究人员大多在寻找提高计算时间(即并行计算或高性能计算(HPC)资源)的方法来管理主要来自出租车GPS数据的大型城市规模数据集(Hu et al., 2017;Ma等人,2019)。
为了进一步开发计算机的无限计算能力,先进的机器学习技术也被开发。分析驾驶模式和识别不安全驾驶行为特征的任务已经在driving analytics (Vlahogianni and)的文献中得到了广泛的研究(Barmpounakis,2017a:Kang and Baneriee,2018)
理解驾驶行为和检测不安全、异常驾驶特征的能力,催生了大量旨在改善驾驶行为、帮助驾驶员养成更高效、更安全驾驶习惯的应用。
此外,驾驶行为分析对于道路运营商确保交通效率和改善交通状况的交通管理和控制非常有用(Hu et al.2015)。
最后,利用保险telematics市场的不安全驾驶行为检测系统销售基于使用的保险方案
上面的复杂性用图1所示的逐步方法来描述。这种逐步的方法是接下来分析的基础。

移动众感的关键问题 mobile crowdsensing
大规模的现象,比如理解驾驶行为,并不能简单地由一个人来衡量(Ma et al., 2015),因此,研究人员利用当今智能手机惊人的感知能力来收集大量的基本驾驶数据。
根据Abdulazim等人(2013),智能手机传感器可以分为三组:
- 运动传感器,包括加速度计、陀螺仪和磁强计(如罗盘)
- 位置传感器,例如全球定位系统(GPS),通常用于户外设置和基于网络的位置服务
- 环境传感器,包括光传感器、麦克风和接近传感器
由于有了这些组件,智能手机已经被用作感知和计算数据的有用工具,引入了移动众感技术。
智能手机的一个明显优势是有大量的潜在参与者有资格参与数据收集的程序。这依赖于智能手机更有可能向用户提供即时反馈,因为用户总是在骚扰他们,这可能会增加长期参与的意愿(Jariyasunant et al, 2012)。
值得注意的是,收集实时数据的能力扩大了研究人员检测高度动态事件的机会(Mashhadi和Capra, 2011)。人们无论走到哪里都愿意随身携带手机,这一事实为开发用于大规模传感目的的成本效益高的系统提供了机会(Ganti等人,2011年)。
不过要让移动众感系统发挥最大潜力,还需要充分解决一些问题和顾虑,比如如何保证数据质量,如何解决电池耗尽问题,以及如何保证隐私和安全问题。下面几节将进一步讨论这些问题。
Data quality 数据质量
从文献来看,数据质量受到两个主要因素的显著影响
用户的可靠性,通常从可信度和代表性两个维度来考察。
- 数据的可信度是指当参与者误解了所要求的任务,犯了错误,甚至故意欺骗系统,从而导致错误的结果(Kanhere, 2013)。因此,捕获的数据可能本质上是嘈杂的,可能需要额外的验证或审查。
- 还考虑了数据完整性的挑战,即验证收集的数据确实来自用户的设备,并在声称的位置收集(Mashhadi和Capra, 2011)。为了实现完整性,感知信息必须能够代表用户的行为和习惯。
- 移动众感系统的关键因素是任何人都可以参与其中。但是,应该考虑到参加者的代表性,并不是每个人都有兴趣参加这种制度。特别是在使用移动众感技术来监测大规模现象时,人群的代表性是一个重要的因素(Ganti et al., 2011)。只有当许多个人提供相关信息时,才能准确地测量这些现象。
- 代表性的关键问题通常被对数据质量和整体系统性能有重大影响的研究人员忽视。
影响数据质量的第二个因素来自智能手机的技术特征。
- 移动设备的集合,他们的感知,计算,存储和通信能力可能会有很大的不同。
- 智能手机运行几种不同的操作系统,最著名的是安卓(Android)和iOS,这些系统经常进行升级,以提高它们的功能和能力。在传感过程中应该考虑到这一点,因为它们直接关系到数据的质量。
- 一些设备电池能量有限,计算能力低,传输带宽有限(Cao和Lin, 2017)。
- 此外,同一类型的数据可能会从不同的传感器收集,例如位置数据可能会从GPS或Wi-Fi收集,因此质量会有所不同。
- 需要考虑的另一个方面是,不同类型的数据可以用于相同的目的,但质量和资源消耗的权衡不同(Ganti et al., 2011)。
处理群众感知数据时的另一个问题是,如果把智能手机放在口袋或袋子里,可能会收集周围的噪音。
相同的传感器可以在不同的条件下感知相同类型的数据,例如,如果该设备被自由地放置在车辆中或是手持的。
- 关键的考虑也应该给予设备安置在车辆。
- 设备的位置和方向显著影响收集数据的质量,因此最近的研究集中在如何将智能手机传感器收集的数据与车辆的运动相匹配(Vlahogianni and Barmpounakis, 2017a)。
- 在Wahlstrom等人(2019)中,研究人员遇到了推断智能手机在车内的位置的问题,例如,通过开发一种基于核聚类的方法,手机是否被放在乘客座位上,是否在中控台上,是否由驾驶员持有,是否被放在坐骑上。
- Ghose等人(2016)开发了一个方向校正模块,以便将智能手机的加速度计读数从设备的坐标系统转换到车辆的坐标系统。
Energy limitations 能量限制
尽管大多数用户每天都要给智能手机充电,但在引入众感应用时,电池消耗的显著增加是一个重要问题。
- 从感知、处理到数据传输,众感平台的各个方面都在消耗能量(Kanhere, 2013),智能手机的电池寿命相对较短,限制了设备用于连续感知目的的使用(Birenboim和Shoval, 2015)。
- 因此,在需要连续实时数据的情况下,很难获得准确的数据。更具体地说,不同的传感器以不同的方式消耗智能手机电池,而与此同时,它们感知相同类型数据的准确性却不同。根据功率测量,可以将传感器从最好到更坏(Lin et al., 2010);
- 例如,在电池消耗的情况下,最好的选择是使用Wi-Fi,然后是3G,最后是GPS,而在精确度方面,最好的传感器是GPS,然后是Wi-Fi,最后是3G。需要特别关注GPS采样率,因为它不仅会显著影响能量消耗,而且还会影响数据的质量(Byon et al., 2007)。
Privacy and security 隐私和安全
Boguslaw和Westin(1968)或许给出了对信息隐私最相关的定义:“信息隐私涉及个人决定何时、如何以及在何种程度上将有关他或她的信息传递给他人的权利。”
在移动众感方案中,隐私是参与者对自己敏感信息的发布保持控制的保证。
这包括对信息的保护,这些信息可以从传感器读数本身以及用户与参与式传感系统的交互中推断出来(Christin等人,2011)。
大量的研究工作集中在解决隐私问题,特别是在基于位置的应用程序和检测移动模式的系统。
大多数研究提出了几种保护参与者隐私的技术,如匿名、假名、空间隐身、数据干扰和聚集(Christin, 2016)。
然而,所有这些方法仍然侧重于提供一种机制,每次解决一种特定的隐私威胁,但没有一种方法能够解决全部的隐私问题。
Understanding data 理解数据
如果有效地使用移动众感,就可以获得大量数据进行进一步分析。
然而,上述约束和限制的存在使得在使用数据调查驾驶行为之前必须插入一系列数据清理程序。
这些步骤通常包括噪声排除和特征提取。特征工程是训练机器学习算法时最需要的数据准备过程(Etemad et al. 2018)。
Data preparation 数据准备
处理噪音被认为是众包智能手机数据的第一个挑战。
- 噪音可能是来自其他交通工具(公交、地铁等)、步行、智能手机使用、与公共交通相关的基础设施以及乘客出行的数据。
- 噪声数据的另一个重要来源是重力对加速度计测量值的影响(Hemminki et al. 2013;Shin等,2015)。
- GPS测量的水平精度,与所有必要的值一起返回,已用于去除噪声数据(Ghose等)。
- 而其他研究人员则使用了更复杂的方法,如输入延迟神经网络(IDNN) (Noureldin et al. 2011)或卡尔曼滤波器(Wahlstrom et al. 2015b)。
- 在最近的一项研究中,研究人员进行了以下数据预处理序列(Lu等,2018)
- i)使用低通滤波器进行数据滤波
- ii)从智能手机重新定位到车辆坐标
- ii)滑动道(滑动道)以提高所收集数据的质量
- 在多篇论文中(Eren et al., 2012: Bose et al..)(2018)使用低通滤波器或简单的移动平均来消除噪声。
- 其他研究人员使用磁强计数据从加速度计和陀螺仪数据中过滤有噪声的样本(Eftekhari和Chatee. 2016)。
- 智能手机噪音这个问题依赖于许多因素。比如不同的设备,传感器,灵敏性,定位或记录频率。
- 应遵循不同的技术,而不是基于数据来源,而是基于这些数据将如何对待每个案例(Paefgen et al. 2012: He et al. 2014: Kanarachos et al..)
Feature engineering for trip information 出行信息的特征工程
数据预处理之后通常是特征提取。
应用不同的建模工具是为了:(Stipancic et al., 2018)
- 识别来自不同模式的出行
- 识别用户是司机还是乘客,并保持与司机相对应的有效出行以供进一步分析
- 检测碰撞
Mode detection 模式检测
检测汽车行程是一项相对简单的任务,主要基于GPS和加速计的速度信息(Feng and Timmermans, 2013;Shin等,2015)。
然而,在相关研究中可以发现一些挑战。
例如,在拥堵的城市道路中识别不同模式时,GPS信息甚至可能会让先进的机器学习工具感到困惑(Efthymiou等,2019)。为了解决这一问题,研究人员将GPS与地理信息系统(GIS)平台的使用相结合(Stenneth et al., 2011)。
由于GPS传感器会耗尽智能手机的电池,而且在没有优化的情况下,GPS传感器的准确性也存在问题,所以其他研究人员转向了只能从加速度计获得数据的其他解决方案(Hemminki等,2013)。
当单独使用加速度计数据时,研究人员也转向基于峰值或基于段的特征(Hemminki等,2013)。
然而,大多数时候,GPS和加速度计数据的统计特性,同时检测到的变化模式最后一组特性中扮演一个重要的角色(吴et al ., 2016)。
在回顾的大多数情况下,将数据分割为时间窗口是一种可以得到准确结果的做法。
根据Nikolic和Bierlaire(2017)的说法,时域和频域特征是从智能手机数据中检测出行模式最常见的特征。
在用于行程模式检测的方法方面,由于加速度值所提供的信息有限,研究人员强调了概率方法的价值。
具体来说,几种旅行模式的相似值范围使得很难对模式进行准确的分类并区分公交车和汽车,或检测自行车(Wu et al., 2016)。
基于规则和概率的方法似乎超越了Eftekhari和Chatee(2016)中所述的限制。
Passenger/driver recognition 乘客/司机 识别
乘客/司机旅行识别比模式检测更复杂,而且对于准确识别司机的配置文件至关重要,因为它需要精确的高分辨率数据,以便分析和识别用户的微活动,这些模式可能有助于检测驾驶(Wahlstrom et al ., 2015b)。
一些研究强调了在试图确定乘客行程时所面临的挑战,并提出了在同一行程中需要来自多个设备的数据的方法(Wahlstrom等。Torres等人2019)使用机器学习模型来区分司机和乘客。
根据作者的说法,使他们的任务具有挑战性的两个原因是:
1)事件发生的时间窗短
2)在事件期间驾驶员行为的可变性
他们的结论是,使用来自不同传感器的数据可以增加模型的可预测性。
另一方面,在lohnson和Rajamani(2019)中,作者使用了来自智能手机运动传感器的数据。
可以看出,虽然不需要使用多个设备或外部硬件就可以很好地检测到智能手机的位置,但是当智能手机不在静态位置时,算法的可检测性降低了。
在Bo et al.(2013)中,驾驶员检测是基于进入车辆时的数据,从哪边发生,是在前座还是在后座。
He等人(2014)提供了另一种有趣的方法,当使用多个设备时,可以检测相对的左右和前后位置。
feature engineering for driving performance 驾驶性能的特征工程
应用数据挖掘技术是为了理解通过智能手机传感器监控的一些基本机动和驾驶事件。更具体地说,机器学习方法被用于检测攻击性行为,如剧烈刹车、加速和转弯事件,并通过识别驾驶时的移动使用来识别驾驶员的分心。
- 大多数关注于驾驶分析的研究已经开发出了识别严重加速和刹车事件的系统。
- Ghose等人(2016)提出了一种融合算法,该算法以GPS、加速度计、车辆位置数据和连续行驶点的时差作为输入,能够区分一个行驶周期内的正常加速与剧烈加速和刹车。
- Predic和Stojanovic(2015)开发了一种先进的机器学习分类器,用于检测异常机动行为,如过度刹车、突然变道、不安全转弯、超速和路线偏离。
- Wahlstrom等人(2015b)也发现了harsh cornering,GPS测量用于检测驾驶员是否发生了危险的转弯事件。
另一个有趣的特点是开车时使用手机。这些信息主要用于判断驾驶员是否在实际驾驶任务中分心(Mantouka et al., 2019;Papadimitriou等,2019年)。
- 识别次要任务(如开车时发短信、打电话)不仅可以更好地了解司机的行为和分心,还可以清除手机粗暴移动所产生的噪音。
- 具体来说,驾驶时使用手机可能会触发智能手机传感器,从而影响harsh事件的检测过程和关键事件的阈值。对这些运动的识别可以减少false positive事件,提高方法的检测能力(Vahogianni and Barmpounakis. 2017a)
- 在Ahmed(2018)研究人员已经识别出司机是否在开车时发短信、打电话或阅读。为了检测这类任务,他们使用基于过滤器的方法进行特征提取,使用基于线性相关和信息增益的两步过程。
目前的研究重点是识别能够减少燃料消耗,从而减少空气污染物的环保驾驶习惯。
- 生态驾驶可以通过描述车辆和交通状况的指标来检测,如发动机转速和齿轮对以及车辆动能的变化(Andrieu et al., 2012)。
- 在缺乏这些数据的情况下,数据挖掘技术仅应用于速度和加速措施,以检测导致高效燃料消耗的驾驶模式。
- 为了了解驾驶员是否采取了生态驾驶行为,提取的主要特征为:超速、加速和转向率(Castignani et al., 2013)。
Modeling driver’s behavior 驾驶员行为建模
理解驾驶员行为是提高道路安全、优化网络服务水平的关键。
对智能手机的大规模研究表明,当司机受到监控时,他的行为相对安全(Johnson and Trivedi, 2011)。
从统计方法到先进的机器学习和计算智能,研究人员使用了多种方法来高效准确地模拟驾驶行为。
表1详细总结了驾驶行为分析领域中最重要的文献的特征、智能手机传感器、方法和输出。
统计方法
一些研究人员试图在描述驾驶行为的特征之间发现有意义的相关性。
- Paefgen等人(2012)提出了一系列重要的统计指标,以及手机和一个参考IMU单元事件记录之间的相关性。
- Chakravarty等(2013)计算了特定时间内个体驾驶员的风险指数。这种情况下的风险函数考虑了风险和异常操作的数量,如急转弯,剧烈刹车和加速,硬颠簸。
- Bejani和Ghatee(2018)将几种驾驶特征的统计分析作为数据准备和更复杂的驾驶行为建模的中间步骤。
另一种研究开发了一种混合效应模型,以了解超速、剧烈机动、剧烈加速和剧烈刹车等行为指标是否可以作为驾驶员分心的预测指标,更具体地说,驾驶员驾驶时是否使用手机(Papadimitriou et al., 2019)。
研究结果显示,超速驾驶和严重驾驶事件的数量与驾驶时使用手机呈负相关,这表明分心驾驶在没有其他危险驾驶行为的情况下可以被检测到。
一些研究人员已经应用了简化的阈值方法,以检测几个异常驾驶事件。在某些情况下,这种方法也被用于识别道路异常,如颠簸和坑洞(Fazeen et al., 2012;Bose等,2018年)。
这种检测方法主要依赖于应用于加速度计数据的固定阈值。实验结果表明,加速度计数据的精度在很大程度上取决于环境特征(车内移动位置、车辆条件、道路类型等),这构成了检测方法的不灵活性(Ouyang等。2018)。
由于这一事实,很难在识别危险驾驶事件的传感器数据上定义通用的阈值。
为了克服这种局限性,研究人员将注意力转向了更有前途的机器学习技术,这些技术通常容易转移,对环境的变化更有活力。
用于识别驾驶行为的模式识别方法,如Dynamic Time Warping(DTW) 也经常出现在文献中。
DTW
- DTW允许分组相似的移动模式,即使在两个系列中对应的元素不是完全一致的。
- 首先,对两个给定的时间序列构造网格,然后计算各元素之间的距离。DTW算法估计通过网格的最优路径,使总距离最小。
DTW的相关研究
- lohnson和Trivedi(2011)提出了一种利用DTW检测强势转弯、加速、刹车和变道事件的新系统。
- Engelbrecht et al。(2016)作者DIW用来检测驾驶事件,然后利用启发式、安全等事件分类器进行分类或鲁莽的,该方法的结果与极大似然方法和结果显示,后者表现更好的分类不同的驾驶动作。
- 最近的研究使用DTW对横向机动进行分类,利用陀螺仪和重力传感器的融合来获取角速度(Singh等。2017)。
DTW的优缺点
- 虽然DTW由于在比较timeseries数据方面的快速和容易实现而被广泛使用,但由于它高度依赖于预定义的阈值,因此不容易转移。
机器学习和计算智能
尽管大量的文献使用统计分析方法来调查几种驾驶行为,但在过去的几十年里,机器学习方法已经在这个领域取得了进展。
最近的研究彻底研究了用于识别驾驶行为的各种机器学习技术(Chan et al., 2019;Elassad et al . .)
本文的目的是讨论与智能手机感知数据相关的最重要的好处和挑战。
Bhoraskar等人(2012)使用了机器学习(ML)技术来识别碰撞和刹车事件,尽管有乐观的结果,作者指出过滤和机器学习技术(k-means聚类和支持向量机-SVM)对于更好地识别恶劣事件的重要性。
Hong et al.(2014)采用朴素Baves分类器识别攻击性驾驶风格,准确率达90%。
在另一项研究(Saiprasert et al., 2013)中使用的模式匹配算法在纵向事件和横向事件中都优于基于规则的算法,
而在Saiprasert和Pattara-Atikom(2013)中使用了相同的技术来识别异常超速事件。
Fazeen等人(2012)利用三轴加速度计来分析驾驶行为和检测道路异常(坑洼、凹凸不平的道路)。它们的分类系统具有较高的识别精度,特别是对粗糙或不平坦道路的识别。
Saiprasert等人(2017)利用加速度计和陀螺仪数据,采用模糊逻辑和基于规则的算法来检测驾驶行为,如剧烈加速、刹车或主动转向。
Koh和Kang(2015)研究人员使用带周期图的高斯混合模型(CMM)对驾驶行为从平稳到攻击性行为的梯度,特别关注老年司机,进行分类。由于他们的数据集(指老年驾驶员的行为)的敏感性,他们强调了GMM在准确分类驾驶风格方面的局限性。
这些研究的主要问题是硬件(传感器和智能手机)的多样性,数据收集期间的天气条件,智能手机的位置(即使它不是固定的)等,使这些技术难以转移,并提出作为一个通用的解决方案
还有一些研究者致力于通过实现分类算法来识别驾驶员的状态。
- Yi等人(2019)比较了几种分类算法在识别三种不同驾驶状态(正常、嗜睡和攻击性)方面的表现。结果表明,与其它分类器(k近邻、决策树、支持向量机)相比,随机森林具有更高的总体准确率。
- 在Vlahogianni and Barmpounakis (2017a)的研究中,MODLEM算法比其他分类算法在利用智能手机加速度计的数据检测恶劣事件方面取得了最大的精确度。
- Mantouka等人(2019)开发了一种两步k-means聚类算法,最初将主动出行与非主动出行区分开来,然后根据驾驶员的分心和风险承担进一步对出行进行聚类。
由于异常驾驶行为比正常驾驶行为出现的频率要低,因此建模的主要挑战是处理不平衡数据集。此外,还没有明确如何定义ground truth;因此,不同方法和数据集之间的比较不可能是通用的。
- Meseguer等人(2017)使用神经网络通过速度和加速度测量来识别驾驶员的攻击性程度。
- Eftekhari和Ghatee(2019)评估了两种分类算法(决策树和朴素贝叶斯)的性能,并将其与具有3个隐藏层的神经网络进行了比较。他们的发现表明,神经网络在检测驾驶动作方面优于其他方法。然而,由于模型的训练和验证所需的计算能力显著增加,一些任务需要离线执行。
从不同的运输相关研究尝试中可以看出,ML技术比统计方法具有显著优势(Karlaftis和Vlahogianni, 2011)。
随着大量智能手机数据集的可用性,我们可以看到,统计方法可以提供对数据集的第一个洞察,需要更先进的技术,以设计准确和高效的解决方案,以应对不同的挑战。
- 在Predic和Stojanovic(2015)中,他们开发了先进的ML分类器来检测恶劣的驾驶模式,并报告了与基于标准差熵、能量、均值等统计指标的加速度计数据活性分析的经典方法相比,改进的结果。
此外,如文献所示,研究人员通常在检测到单个事件或将异常驾驶行为与安全驾驶分离时使用统计方法。相反,当驾驶行为的整个范围被调查和许多不同的驾驶剖面被检测时,ML方法被使用。 - Chan et al.(2019)在分类精度方面比较了不同的方法。在这里,我们强调的指标,作为输入驾驶行为识别和补充。提供有关数据收集过程的进一步信息。
值得注意的是,在这项工作中,我们避免使用绝对的精度度量来比较不同的方法,因为仍然存在一些挑战,可能导致完全误导的结果。
Applications assessing and assisting drivers
扩展知识领域的推动分析了研究人员和其他人员的机会开发先进的应用程序的评估驾驶行为以及驾驶辅助系统,旨在提高司机的道路安全性能,提高意识和空气污染,改善驾驶体验。
最近的一项研究收集了最相关的驾驶辅助系统,可以在Meiring和Myburgh找到(2015)。
这里的重点是利用移动人群感知数据开发此类系统,并使用智能手机作为系统与驾驶员之间唯一的通信平台。
Drivers’ assistance and recommendation systems
驾驶行为分析的进步导致了先进驾驶辅助系统(ADAS) 的发展。由于ADAS是一种创新的、用户友好的技术,能够提供实时驾驶提示,满足安全和生态标准,因此越来越受到人们的广泛关注(Kaur和Sobti, 2017)。
一些最广泛使用的ADAS包括自适应巡航控制、导航辅助和改道系统、车道保持辅助和驾驶员困倦检测。这类系统的开发主要是为了提高道路安全性,其次是为了提高旅行舒适度和驾驶体验。
驾驶分析技术的进步,加上当今设备无线性能的提高,使得实时ADAS的开发成为可能。具体的研究集中在实时驾驶员分心检测上,该检测主要基于车道位置和转向控制等驾驶性能测量以及速度控制测量(Liu et al., 2016)。
虽然大多数ADAS专注于确保道路安全,减少交通事故,在情况下驾驶体验改善或提升生态驾驶的问题,研究人员已经开发出司机推荐系统与ADAS的广泛应用,研究驾驶推荐系统仍处于初级阶段。
Magana和Organero(2011)的研究人员开发了一个生态驾驶推荐系统,该系统首先检测驾驶风格,然后使用随机森林对驾驶行为进行分类,并提供有用的生态驾驶提示。
Araujo等人(2012)已研发环保驾驶教练,以推广省油高效驾驶。首先,他们识别驾驶行为和车辆状况,然后,他们推荐一个最受欢迎的环保驾驶技巧,如“关闭引擎”,“早些换挡”,“你的加速太高了”。
另一项研究开发了一种情境感知驾驶辅助系统,旨在促进节油驾驶(Gilman等。2014年),研究人员识别攻击性驾驶行为,然后将其与交通和天气状况一起放在地图上,以调查特定的驾驶模式。通过这种方式,他们能够就如何更有效率地行驶到特定的路线提出建议,然后就如何在未来提高他们的驾驶性能提出建议。
这类系统已被证明可以改善驾驶行为,并引导人们采用更平稳、更安全的驾驶习惯。
正如Staubach等人(2014)所讨论的那样,接受生态驾驶建议的驾驶员会采取一种不那么苛刻的机动行为,并保持恒定的速度。
另一项研究强调了在这类系统中引入游戏化方面的重要性,以获得驾驶员对系统的参与,并进一步改善他们的行为(Magana和Organero, 2014)。
游戏化的概念是指将娱乐和游戏导向的设计方法包含在非游戏环境中,如移动众感应用(Wells et al., 2014)。
一个有效的游戏化框架是建立在一系列量化既定目标(改善驾驶行为、采用环保驾驶习惯、降低油耗等)成功程度的指标之上的,而这些目标是通过一系列任务来实现的。
Drivers’ scoring systems
在过去的几十年里,也有一个发展计分和行为评估系统的趋势。
研究人员和应用程序开发人员试图为人们之间的良性竞争和比较创造环境,以提高他们对重大问题的意识,认为后者将改善他们的行为。
在这种情况下,评分方法以及排名和基准测试技术的创造得到了加强,如前所述,得分和通过完成特定任务获得名次是最常见的游戏化方面,与排行榜、成就相比、礼物等。在游戏化框架下,用户还可以与他人进行交流。比较他们的表现和竞争(Vlahogianni and Barmpounakis, 2017b)。
- Smith等人(2016)开发了一个系统的驾驶行为评分框架,该框架主要包括三个方面:车队管理应用的风险评分、操作评分和经济评分。
- DriveSafe是一款检测司机何时从驾驶任务中分心并根据驾驶行为给其打分的应用程序(Bergasa等人,2014)。该系统首先识别加速、刹车和转弯以及车道漂移和转弯,然后根据比赛的数量和强度给每位车手打分。
- Castignani等人(2015)基于模糊推理系统使用数据融合来检测危险和攻击性驾驶事件。随后,每次行程中确定的驾驶事件数与天气条件和行程当天的时间相结合,以提供从0到100的行程分数。
- Araujo等人(2012)开发了一种驾驶员评价系统,以提高驾驶员对生态驾驶的认识。为此,智能手机传感器采集速度、油耗和加速度测量值,然后根据预定义的阈值对驾驶条件进行分类,然后使用模糊逻辑方法评估驾驶提示信息的性能并选择最合适的显示给驾驶员。
虽然计分系统被认为是提高驾驶员意识的有效方法,但一些研究人员强调了获得真正的节约作为改善个人驾驶行为的激励的重要性。
- 保险收费系统在过去十年中得到了越来越多的关注。保险公司已经建立了多种保险政策,根据车辆使用情况和驾驶行为特征向司机收费,包括PAYD和PHYD系统(Wahlstrom et al, 2017)。
- Tselentis等人(2017)报道了最流行的基于使用的保险(UBI)方案。正如他们所强调的,有证据表明UBI的实施将会激励驾驶员改善他们的驾驶行为,并通过采用安全和更有效的驾驶习惯来改变他们的行为。
- Handel等人(2014)也广泛讨论了基于智能手机传感器收集的驾驶特征来构建保险计划的机会。后者强调了有意识地设计UBI的重要性,因为也存在提供的反馈或建议被错误地感知的风险。
Main challenges and possible caveats(警告)
从所提出的方法框架的详细概述,可以清楚地看出驾驶行为分析是一个多维的问题。
在本节中,我们强调了通过智能手机感知数据理解驾驶行为过程中最关键的挑战。
我们还讨论了一些大多数时候被忽视的警告。表2提供了一些针对文献中提出的挑战的指示性解决方案。
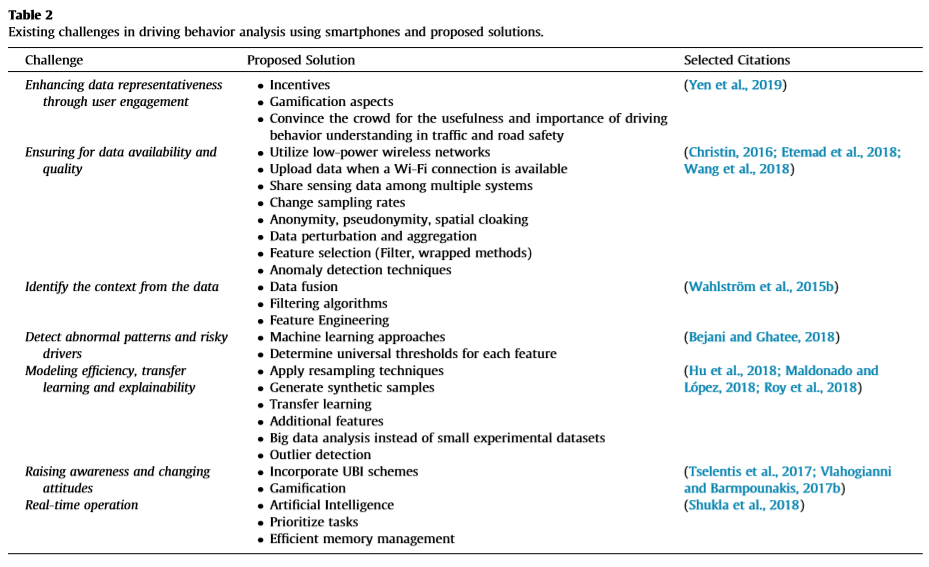
| 挑战 | 提出的方法 | 选择的引用 |
| 通过用户参与增强数据的代表性 |
|
(Yen et al.,2019年) |
| 确保数据的可用性和质量 |
|
(Christin,2016;Etemad et al.,2018;Wang et al.,2018) |
| 从数据中识别上下文 |
|
(Wahlstrom et al.,2015b) |
| 检测异常模式和危险司机 |
|
(Bejani and Ghatee,2018) |
| 建模效率,迁移学习和可解释性 |
|
(Hu et al.,2018;Maldonado and Lopez,2018;Roy et al.,2018) |
| 提高意识,改变态度 |
|
(Tselentics et al.,2017;Vlahogianni and Barmpounakis,2017b) |
| 实时操作 |
|
(Shukla et al.,2018) |
Challenge 1: Enhancing data representativeness through user engagement 通过用户参与增强数据的代表性
在移动众感系统中,用户本身是最基本的组成部分之一,因此,用户与系统的互动至关重要。大多数研究旨在识别通用的驾驶行为并确定控制不安全驾驶行为的一般规则
由于驾驶行为的识别依赖于数据驱动的方法,因此数据的可变性非常重要。实际参与数据收集过程的目标人群的比例针对性地影响数据的代表性,也不可避免地影响数据的质量。
此外,用户的长期参与也是至关重要的,因为人类的行为与时间有关的复杂性,以及它随着时间和各种刺激的缓慢或不变化。
在文献中,有几种技术被确定为确保用户长期参与众感系统的成功干预手段。许多研究人员强调了为用户提供奖励以长期参与众感系统的重要性(Yen et al., 2019)。
在Musicant和Lotan(2016)中,研究人员指出了群体激励在激励年轻司机方面的有效性。虽然最近已经部署了几种类型的激励,但它们能在多大程度上提高人们的意识,并驱动行为改变,还有待研究。
此外,可用数据集中的行为可变性通常与模型泛化能力的重大影响被忽略。
研究人员倾向于找到大型数据集作为锻炼和发展他们的机器学习的实验技能,将意识到他们的模型将很快成为过时(速降精度指标),随着数据的增长,主要是由于这一事实的初始样本不能代表用户的特征。
但是,即使我们试图控制样本的统计特征,现实也会再次让我们吃惊:
- 首先,由于隐私的限制,大多数时候研究人员无法获得样本特征(比如年龄、性别)。
- 其次,收集和处理一个大数据集需要花费大量的时间,特别是如果是为了确保特定用户和行为的代表性。
通过引入不断培训的过程和处理模型对变化的弹性的过程,可以有效地解决上述问题。
Challenge 2: Ensuring for data availability and quality
数据可用性和质量是交通文献中每一种数据驱动方法的基本成分。
由于几个原因,可用性不能得到保证。
- 首先,数据可能是私有的或限制访问。最近,在欧盟《一般数据保护条例》(GDPR)的严格规定下,从人群中感知数据变得更加具有挑战性,特别是在数据隐私和安全方面。保护系统不受未授权方侵犯的技术是主要需求。到目前为止,研究人员似乎忽视了制定确保数据隐私策略的重要性和意义。
- 此外,可能无法获得所需分辨率的数据。事实上,某些驾驶现象(例如,智能手机的干扰,变道)可能需要非常详细的记录,而其他的可以在较粗糙的水平上很容易观察到。与开发的应用程序相关,识别正确的数据分辨率在文献中被严重忽视,并显著影响检测能力和对驾驶任务的理解。但是,即使有人选择获得智能手机传感器的大部分功能(通常是100赫兹的分辨率),这也可能导致由于电池耗尽数据采集方案不可持续。此外,车辆受驾驶环境、交通条件等不同因素的影响,一些与变道现象或变道选择相关的任务也变得更加具有挑战性。车辆的类型等(Barmpounakis等。(2020),虽然提高采样率对于提高模型的预测能力是可取的,但这可能会对用户体验产生负面影响,因为设备资源的快速消耗可能会阻碍用户对系统的贡献在以前的挑战
由于智能手机设备的不确定性,数据质量可能会对智能手机感知数据的理解产生深远的影响:
- 是多种技术
- 可以放置在任何地方的用户或车辆
- 配备可以以不同频率异步记录的传感器。
数据重定向和同步策略通常应用于正确的数据,并将其置于准备建模的表单中,这需要很大的努力,但也不能确保不会出现故障和干扰。
智能手机众感框架中的质量保证方案对于驾驶分析尤为必要,因为现象检测依赖于极值,通常包括噪声过滤、数据重定向和地理标记(Vlahogianni and Barmpounakis, 2017a)。
Challenge 3: Identify the context from the data
用户行为受交通方式、路网类型、交通控制、天气条件等因素的显著影响。
为了检测关键模式以及理解和建模行为特征,应该通过联合考虑其他外部信息,从数据本身中提取数据的上下文。
处理从数据中提取上下文的问题对模型弹性有重要的附加值,因为从原始数据中提取的特征的质量主要反映了系统的整体准确性(Ignatov, 2018)。
但是,我们应该如何通过用户不可知的实验和盲目的众感系统来理解上下文呢?
在用户不可知的环境中,从多感官数据派生上下文的主要工具是:
- 数据融合
- 特征工程
- 用户/行为分析
当涉及到确保所有可用信息都能被综合考虑时,数据融合是很重要的;
- 可以将带有智能手机传感功能的天气数据和社交媒体信息融合,以提取由于天气变化或不同旅行目的而产生的移动模式变化。
特征工程能够识别那些对上下文感知至关重要的特征。 - Mantouka等人(2019)对加速度计信号进行处理,提取每公里剧烈加速和每公里剧烈刹车等特征,然后用于驾驶行为检测。
- 另一个通常首先被发现的特征是旅行模式 travel mode(Nikolic和Bierlaire, 2017: Efthymiou等人…2019)。
- 首先采用模态检测技术,
- 然后根据检测到的模态对数据进行清洗,因为不同的动力学导致不同模态间的噪声不一致。
- 显然,更多可用的数据源意味着更强的识别关键模式的能力,从而更清楚地了解数据背后的上下文。
现有众感系统之间的互操作性和透明性对于数据重用和迁移学习非常重要。
Challenge 4: Detect abnorml patterns and risky drivers
大多数研究遵循的一个共同的研究路线是基于阈值的检测偏离正常驾驶的方法。
矛盾修饰法在于,许多研究得出的结论是,没有通用的阈值可以应用,因为智能手机传感器的技术变异性影响提取的信号,当然也影响被认为是异常的阈值。
事实上,基于阈值的方法是检测异常驾驶模式的第一步,特别是在没有先验知识存在的系统中(例如,可用于监督学习的注释样本)。
但是,需要一种与设备无关的上下文无关的方法来设置阈值,以确保后者不受设备微移动、传感器特性和设备方向和定位的影响。甚至考虑一个非阈值方法也将有利于建立一个通用的驱动行为分析框架.
在极端行为检测中,另一个通常被忽视的方面是如何从基于旅行的特征归纳到用户特定的行为,这意味着需要监视司机多长时间才能理解他的行为。这在宏观分析层面上是非常关键的,系统应该向用户提供建议,让用户如何改进自己的驾驶风格,成为更安全、更高效的驾驶员。
要对一个人进行多长时间的监控,才能观察到他的驾驶特征的收敛性,这个问题的答案不是单方面的。它取决于用户对道路的感知和态度,也取决于道路、交通和控制条件。
最近的一项研究试图确定检测单一驾驶特征(如攻击性)时的基本数据量(Stavrakaki等)。然而,文献中却缺少一种方法框架来估计每个驾驶员需要收集多少驾驶数据,从而对其整体驾驶行为有一个清晰的了解。
Challenge 5: Modeling efficiency, transfer learning and explainability
有效的模型是既准确又不产生系统误差的模型。在使用数据驱动技术处理的高度不稳定的问题中,获得精确性,但同时注意过度训练是最重要的(Karlaftis and Vlahogianni, 2011)。
对于智能手机感知数据集通常是不平衡的(数据集中很少出现异常驾驶甚至事故),有效模型的开发是一个繁琐的过程。
当研究人员转向重采样技术或生成合成数据集时,当涉及到哪种技术适合每个问题时,不同的挑战就出现了。
例如,是否对数据集进行重新采样以使两个类都得到相同的表示,或者是否一个类与另一个类比例过大,如果是,大多少?
虽然这些问题已经被部分的文献解决,丰富现有的数据集更多的特征也可以提供显著的改进来应对这一挑战。
鉴于极端行为缺乏代表性,迁移学习的使用似乎也是一条合适的途径。迁移学习和领域适应指的是利用在一种环境中学习到的知识来提高在另一种环境中泛化的情况(Mairai等,2019)。简单地说,迁移学习利用基于另一个问题开发的知识能力,促进对手头问题的学习过程。
ML模型,特别是深度学习模型的主要局限性是训练过程耗时。即使使用具有强大计算能力的硬件,在存在大数据的情况下,训练阶段也不能被忽视,尤其对于实时应用来说,这是一个未来的挑战。
迁移学习可以很好地解决ML模型训练费时的问题,而ML模型可以很容易地解决一些数据限制,如嘈杂的数据和不平衡的数据集。
然而,建立准确的模型不应该是唯一的问题。大多数研究人员经常通过比较完全基于模型精度的方法来遵循最小阻力的路径;然而,在建模精度、模型简单性、适用性和可用性之间有一条“细线”。
研究人员应该记住,产生的模型应该是可操作的,这意味着操作和维护简单,准确到足以产生可靠的结果,并容易集成到复杂的系统。
此外,在强调模型的解释力的情况下,建模应该清楚地解决因果关系的问题。众所周知,相关性并不意味着因果关系。
通过ML建模来解决因果关系——不管是用于函数逼近、模式识别还是时间序列分析——都不是一个简单的过程,可以使用几种统计结构来解决这个问题(Karlaftis和Vlahogianni,2011;Lavrenz等人,2018年)
Challenge 6: Raising awareness and changing attitudes
虽然道路安全是研究人员、从业者甚至司机自己都关心的问题,但并不是每个人都意识到驾驶行为与道路安全水平之间的关系。
重要的是让司机意识到他们驾驶行为的影响。冒险性、攻击性和驾驶任务的分心是驾驶员发生交通事故的主要原因(Hong et al., 2014)。
ADAS的目的是在驾驶过程中支持司机,防止这种不安全行为。另一个日益增长的趋势是交通安全和可持续性的结合。
因此,如前所述,今天的驾驶建议和辅助系统的目标是双重的:促进环保驾驶,同时确保道路安全。
- 在环保驾驶方面,改变驾驶态度似乎更容易,因为这种驾驶方式与金钱成本和节省燃料有关。
- 对于安全驾驶来说,改变人们不安全的驾驶习惯似乎更具挑战性,尤其是因为人们往往会忽视自己驾驶行为的影响。
在这种情况下,也应该给予强有力的激励,因为最终目标不仅是激励司机参与一项事业,而且还提高了他们的意识。
另外一个值得关注的问题是,驾驶推荐系统是以驾驶员与系统持续合作为前提的,在这样的系统中,驾驶员不断地收到提高驾驶效率甚至驾驶体验的驾驶提示和建议。
如果驾驶员不打算接受系统提供的建议,那么系统就失去了它的潜力。
为此,提高驾驶员对其驾驶习惯影响的认识,并确保他们长期参与该系统是至关重要的。
大多数研究人员关注教育和培训的重要性,认为教育和培训是改变驾驶员态度的关键(赵等人,2019),
然而,最近的趋势要求对驾驶行为进行持续监控,即使不是实时提供建议和提示,也要持续不断。
Challenge 7: Real-time operation
直到最近,一小部分文献已经开发出能够实时运行的驾驶行为检测和推荐算法。
然而,由于需要通过对交通的管理来确保当今运输系统的恢复力,道路事故和排放已经出现。
保证驾驶推荐系统的实时运行是迫切需要的。
如前所述,驾驶行为不仅是道路安全的主要贡献者,而且是道路网络状况的主要贡献者,因此,只有开发出易于解释和响应的推荐系统,才能有可能改善驾驶行为。
考虑到人类行为的复杂性以及前面描述的方法上的挑战,未来的研究应该在开发能够实时运行的推荐系统上投入大量精力,特别是如果它们能够提供个性化的建议和提示的话。
先进的计算智能技术有望取得良好的结果,并有效地应对用户定制的实时推荐系统的挑战性任务。
此外,这项任务在联网车辆(CVs)和合作智能交通系统(c-ITS)的新兴环境中至关重要,因为与昂贵的嵌入式相比,智能手机可以在车辆和基础设施之间提供一种成本效益高的通信解决方案。
CVs的通信解决方案,特别是对于转型时期的老车,老车和联网车辆将共享相同的驾驶环境和基础设施(Su等。2012)。
Conclusion
智能手机众感不是一个新兴领域;它作为收集数据的可靠选择正在不断上升。
具体工作试图通过建立一个方法论的框架分析现有文献对驾驶行为的识别和理解,包括四个阶段:数据收集、数据准备、数据挖掘、驾驶行为建模和最后,有价值的信息开发决策和建议制定协助和提高驾驶行为。
分析指出,在依赖基于智能手机的数据和模型时,应该考虑一些普遍存在的挑战。
这些涉及到数据的可用性和质量、代表性、基于上下文的知识提取、模式识别和建模,对行为改变的建议,以及影响评估和实时操作。
讨论现有的挑战和可能的警告表明,基准模型和数据处理程序可以提供有用的信息是什么类型的建模适合于不同的应用程序。
为此,对于确保基于智能手机的数据收集和建模系统的可转移性和可持续性,模型对上下文规范和数据变化的弹性的新度量非常重要。
在数据挖掘和建模方面,人工智能和迁移学习的使用可以提高模型的准确性和泛化能力,同时也保证了模型的灵活性和实时性。
此外,在没有大数据的情况下,现有众感系统之间的互操作性和透明性对于数据重用和迁移学习非常重要。
驾驶行为分析的进步使得驾驶推荐系统能够提供安全驾驶或生态驾驶技术和提示。
尽管有很多证据表明,推荐系统和ADAS有潜力改善交通状况、道路安全和驾驶体验,以充分发挥其潜力,但驾驶员对该系统的接受和长期参与是先决条件。
下一步是设计一种影响评估工具,以衡量这些系统对用户的感知、选择以及对运输系统的影响。
显然,人们对快速、准确的检测模型以及对司机的实时反馈和帮助有着很高的要求。
将最终推动人工智能的部署,以确保从道路上车辆产生的大量数据中,可以出现用户不可知的推荐方案,帮助用户从改进驾驶转向改进移动习惯。
| 一个普通标题 | 一个普通标题 | 一个普通标题 |
|---|---|---|
| 短文本 | 中等文本 | 稍微长一点的文本 |
| 稍微长一点的文本 | 短文本 | 中等文本 |